ERF_ComputeTurbulentViscosity.cpp File Reference
#include "ERF_SurfaceLayer.H"#include "ERF_EddyViscosity.H"#include "ERF_Diffusion.H"#include "ERF_PBLModels.H"#include "ERF_TileNoZ.H"#include "ERF_TerrainMetrics.H"#include "ERF_MoistUtils.H"#include "ERF_RichardsonNumber.H"
Include dependency graph for ERF_ComputeTurbulentViscosity.cpp:

Functions | |
| void | ComputeTurbulentViscosityLES (Vector< std::unique_ptr< MultiFab >> &Tau_lev, const MultiFab &cons_in, MultiFab &eddyViscosity, MultiFab &Hfx1, MultiFab &Hfx2, MultiFab &Hfx3, MultiFab &Diss, const Geometry &geom, bool use_terrain_fitted_coords, Vector< std::unique_ptr< MultiFab >> &mapfac, const std::unique_ptr< MultiFab > &z_phys_nd, const TurbChoice &turbChoice, const Real const_grav, std::unique_ptr< SurfaceLayer > &, const MoistureComponentIndices &moisture_indices, const MultiFab *xvel, const MultiFab *yvel) |
| void | ComputeTurbulentViscosityLES_EB (Vector< std::unique_ptr< MultiFab >> &Tau_lev, const MultiFab &cons_in, MultiFab &eddyViscosity, MultiFab &Hfx1, MultiFab &Hfx2, MultiFab &Hfx3, const Geometry &geom, Vector< std::unique_ptr< MultiFab >> &mapfac, const TurbChoice &turbChoice, const Real const_grav, [[maybe_unused]] const SolverChoice &solverChoice, std::unique_ptr< SurfaceLayer > &, const MoistureComponentIndices &moisture_indices, const eb_ &ebfact, const MultiFab *xvel, const MultiFab *yvel) |
| void | ComputeTurbulentViscosityRANS (Vector< std::unique_ptr< MultiFab >> &, const MultiFab &cons_in, const MultiFab &wdist, MultiFab &eddyViscosity, MultiFab &Hfx1, MultiFab &Hfx2, MultiFab &Hfx3, MultiFab &Diss, const Geometry &geom, bool use_terrain_fitted_coords, Vector< std::unique_ptr< MultiFab >> &, const std::unique_ptr< MultiFab > &z_phys_nd, const TurbChoice &turbChoice, const Real const_grav, std::unique_ptr< SurfaceLayer > &SurfLayer, const MultiFab *z_0) |
| void | ComputeTurbulentViscosity (double dt, const MultiFab &xvel, const MultiFab &yvel, Vector< std::unique_ptr< MultiFab >> &Tau_lev, MultiFab &cons_in, const MultiFab &wdist, MultiFab &eddyViscosity, MultiFab &Hfx1, MultiFab &Hfx2, MultiFab &Hfx3, MultiFab &Diss, const Geometry &geom, Vector< std::unique_ptr< MultiFab >> &mapfac, const std::unique_ptr< MultiFab > &z_phys_nd, const std::unique_ptr< MultiFab > &z_phys_cc, const SolverChoice &solverChoice, std::unique_ptr< SurfaceLayer > &SurfLayer, const MultiFab *z_0, const bool &use_terrain_fitted_coords, const bool &use_moisture, int level, const BCRec *bc_ptr, const eb_ &ebfact, bool vert_only, const MultiFab *qheating_rates) |
Function Documentation
◆ ComputeTurbulentViscosity()
| void ComputeTurbulentViscosity | ( | double | dt, |
| const MultiFab & | xvel, | ||
| const MultiFab & | yvel, | ||
| Vector< std::unique_ptr< MultiFab >> & | Tau_lev, | ||
| MultiFab & | cons_in, | ||
| const MultiFab & | wdist, | ||
| MultiFab & | eddyViscosity, | ||
| MultiFab & | Hfx1, | ||
| MultiFab & | Hfx2, | ||
| MultiFab & | Hfx3, | ||
| MultiFab & | Diss, | ||
| const Geometry & | geom, | ||
| Vector< std::unique_ptr< MultiFab >> & | mapfac, | ||
| const std::unique_ptr< MultiFab > & | z_phys_nd, | ||
| const std::unique_ptr< MultiFab > & | z_phys_cc, | ||
| const SolverChoice & | solverChoice, | ||
| std::unique_ptr< SurfaceLayer > & | SurfLayer, | ||
| const MultiFab * | z_0, | ||
| const bool & | use_terrain_fitted_coords, | ||
| const bool & | use_moisture, | ||
| int | level, | ||
| const BCRec * | bc_ptr, | ||
| const eb_ & | ebfact, | ||
| bool | vert_only, | ||
| const MultiFab * | qheating_rates | ||
| ) |
Wrapper to compute turbulent viscosity with LES or PBL.
- Parameters
-
[in] xvel velocity in x-dir [in] yvel velocity in y-dir [in] Tau_lev strain at this level [in] cons_in cell center conserved quantities [out] eddyViscosity turbulent viscosity [in] Hfx1 heat flux in x-dir [in] Hfx2 heat flux in y-dir [in] Hfx3 heat flux in z-dir [in] Diss dissipation of turbulent kinetic energy [in] geom problem geometry [in] mapfac map factors [in] turbChoice container with turbulence parameters [in] most pointer to Monin-Obukhov class if instantiated [in] vert_only flag for vertical components of eddyViscosity [in] qheating_rates radiation heating rates (SW, LW components)
819 // In PBL mode, the primary purpose of the PBL model is to control vertical transport, so the PBL model sets the vertical viscosity.
820 // Optionally, the PBL model can be run in conjunction with an LES model that sets the horizontal viscosity
823 // ComputeTurbulentViscosityLES populates the LES viscosity for both horizontal and vertical components.
928 cc_mask.BuildMask(geom.Domain(), geom.periodicity(), is_covered, is_notcovered, is_physbnd, is_interior);
void ComputeDiffusivityMRF(const MultiFab &xvel, const MultiFab &yvel, const MultiFab &cons_in, MultiFab &eddyViscosity, const Geometry &geom, const TurbChoice &turbChoice, std::unique_ptr< SurfaceLayer > &SurfLayer, bool use_terrain_fitted_coords, bool use_moisture, int level, const BCRec *bc_ptr, bool, const std::unique_ptr< MultiFab > &z_phys_nd, const std::unique_ptr< MultiFab > &z_phys_cc, const MoistureComponentIndices &moisture_indices)
Definition: ERF_ComputeDiffusivityMRF.cpp:13
void ComputeDiffusivityMYJ(double dt, const MultiFab &xvel, const MultiFab &yvel, MultiFab &cons_in, MultiFab &eddyViscosity, const Geometry &geom, const TurbChoice &, std::unique_ptr< SurfaceLayer > &, bool use_terrain_fitted_coords, bool, int, const BCRec *bc_ptr, bool, const std::unique_ptr< MultiFab > &z_phys_nd, const std::unique_ptr< MultiFab > &z_phys_cc, const MoistureComponentIndices &moisture_indices)
Definition: ERF_ComputeDiffusivityMYJ.cpp:13
void ComputeDiffusivityMYNN25(const MultiFab &xvel, const MultiFab &yvel, const MultiFab &cons_in, MultiFab &eddyViscosity, const Geometry &geom, const TurbChoice &turbChoice, std::unique_ptr< SurfaceLayer > &SurfLayer, bool use_terrain_fitted_coords, bool use_moisture, int level, const BCRec *bc_ptr, bool, const std::unique_ptr< MultiFab > &z_phys_nd, const std::unique_ptr< MultiFab > &z_phys_cc, const MoistureComponentIndices &moisture_indices)
Definition: ERF_ComputeDiffusivityMYNN25.cpp:13
void ComputeDiffusivityMYNNEDMF(const MultiFab &xvel, const MultiFab &yvel, const MultiFab &cons_in, MultiFab &eddyViscosity, const Geometry &geom, const TurbChoice &turbChoice, std::unique_ptr< SurfaceLayer > &SurfLayer, bool use_terrain_fitted_coords, bool use_moisture, int level, const BCRec *bc_ptr, bool, const std::unique_ptr< MultiFab > &z_phys_nd, const std::unique_ptr< MultiFab > &z_phys_cc, const MoistureComponentIndices &moisture_indices)
Definition: ERF_ComputeDiffusivityMYNNEDMF.cpp:4177
void ComputeDiffusivityYSUNew(const MultiFab &xvel, const MultiFab &yvel, const MultiFab &cons_in, MultiFab &eddyViscosity, const Geometry &geom, const TurbChoice &turbChoice, std::unique_ptr< SurfaceLayer > &SurfLayer, bool use_terrain_fitted_coords, bool use_moisture, int level, const BCRec *bc_ptr, bool, const std::unique_ptr< MultiFab > &z_phys_nd, const std::unique_ptr< MultiFab > &z_phys_cc, const MoistureComponentIndices &moisture_indices, const MultiFab *qheating_rates)
Definition: ERF_ComputeDiffusivityYSUNew.cpp:17
void ComputeDiffusivityYSU(const MultiFab &xvel, const MultiFab &yvel, const MultiFab &cons_in, MultiFab &eddyViscosity, const Geometry &geom, const TurbChoice &turbChoice, std::unique_ptr< SurfaceLayer > &SurfLayer, bool use_terrain_fitted_coords, bool, int level, const BCRec *bc_ptr, bool, const std::unique_ptr< MultiFab > &z_phys_nd, const std::unique_ptr< MultiFab > &z_phys_cc, const MoistureComponentIndices &moisture_indices)
Definition: ERF_ComputeDiffusivityYSU.cpp:11
void ComputeTurbulentViscosityRANS(Vector< std::unique_ptr< MultiFab >> &, const MultiFab &cons_in, const MultiFab &wdist, MultiFab &eddyViscosity, MultiFab &Hfx1, MultiFab &Hfx2, MultiFab &Hfx3, MultiFab &Diss, const Geometry &geom, bool use_terrain_fitted_coords, Vector< std::unique_ptr< MultiFab >> &, const std::unique_ptr< MultiFab > &z_phys_nd, const TurbChoice &turbChoice, const Real const_grav, std::unique_ptr< SurfaceLayer > &SurfLayer, const MultiFab *z_0)
Definition: ERF_ComputeTurbulentViscosity.cpp:569
void ComputeTurbulentViscosityLES(Vector< std::unique_ptr< MultiFab >> &Tau_lev, const MultiFab &cons_in, MultiFab &eddyViscosity, MultiFab &Hfx1, MultiFab &Hfx2, MultiFab &Hfx3, MultiFab &Diss, const Geometry &geom, bool use_terrain_fitted_coords, Vector< std::unique_ptr< MultiFab >> &mapfac, const std::unique_ptr< MultiFab > &z_phys_nd, const TurbChoice &turbChoice, const Real const_grav, std::unique_ptr< SurfaceLayer > &, const MoistureComponentIndices &moisture_indices, const MultiFab *xvel, const MultiFab *yvel)
Definition: ERF_ComputeTurbulentViscosity.cpp:30
void ComputeTurbulentViscosityLES_EB(Vector< std::unique_ptr< MultiFab >> &Tau_lev, const MultiFab &cons_in, MultiFab &eddyViscosity, MultiFab &Hfx1, MultiFab &Hfx2, MultiFab &Hfx3, const Geometry &geom, Vector< std::unique_ptr< MultiFab >> &mapfac, const TurbChoice &turbChoice, const Real const_grav, [[maybe_unused]] const SolverChoice &solverChoice, std::unique_ptr< SurfaceLayer > &, const MoistureComponentIndices &moisture_indices, const eb_ &ebfact, const MultiFab *xvel, const MultiFab *yvel)
Definition: ERF_ComputeTurbulentViscosity.cpp:336
void ComputeTurbulentViscosity(double dt, const MultiFab &xvel, const MultiFab &yvel, Vector< std::unique_ptr< MultiFab >> &Tau_lev, MultiFab &cons_in, const MultiFab &wdist, MultiFab &eddyViscosity, MultiFab &Hfx1, MultiFab &Hfx2, MultiFab &Hfx3, MultiFab &Diss, const Geometry &geom, Vector< std::unique_ptr< MultiFab >> &mapfac, const std::unique_ptr< MultiFab > &z_phys_nd, const std::unique_ptr< MultiFab > &z_phys_cc, const SolverChoice &solverChoice, std::unique_ptr< SurfaceLayer > &SurfLayer, const MultiFab *z_0, const bool &use_terrain_fitted_coords, const bool &use_moisture, int level, const BCRec *bc_ptr, const eb_ &ebfact, bool vert_only, const MultiFab *qheating_rates)
Definition: ERF_ComputeTurbulentViscosity.cpp:792
AMREX_ALWAYS_ASSERT(bx.length()[2]==khi+1)
ParallelFor(grown_box, [=] AMREX_GPU_DEVICE(int i, int j, int k) { qrcuten_arr(i, j, k)=Real(0);qscuten_arr(i, j, k)=Real(0);qicuten_arr(i, j, k)=Real(0);})
MoistureComponentIndices moisture_indices
Definition: ERF_DataStruct.H:1441
Definition: ERF_TurbStruct.H:82
Referenced by ERF::advance_dycore().
Here is the call graph for this function:
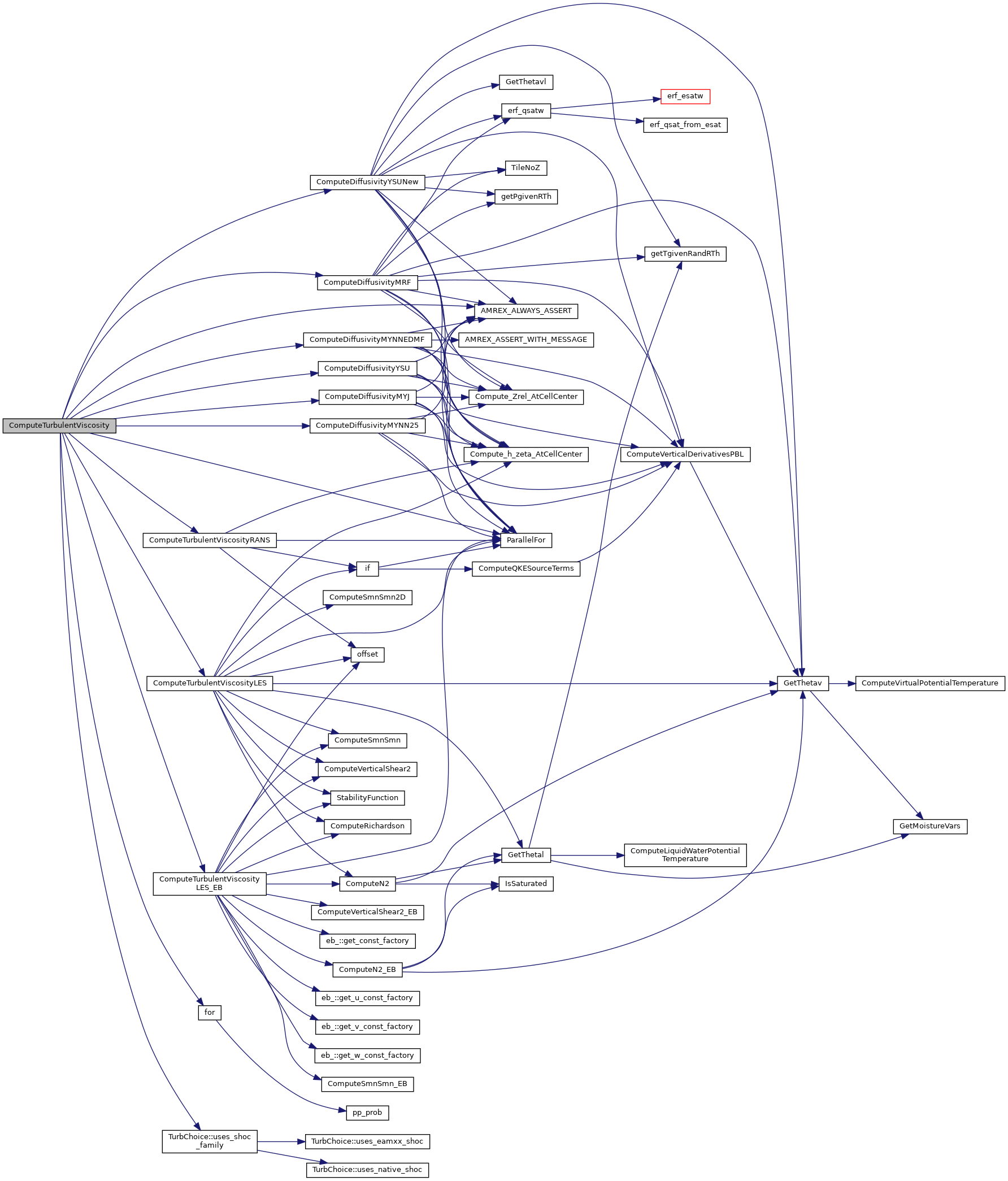
Here is the caller graph for this function:

◆ ComputeTurbulentViscosityLES()
| void ComputeTurbulentViscosityLES | ( | Vector< std::unique_ptr< MultiFab >> & | Tau_lev, |
| const MultiFab & | cons_in, | ||
| MultiFab & | eddyViscosity, | ||
| MultiFab & | Hfx1, | ||
| MultiFab & | Hfx2, | ||
| MultiFab & | Hfx3, | ||
| MultiFab & | Diss, | ||
| const Geometry & | geom, | ||
| bool | use_terrain_fitted_coords, | ||
| Vector< std::unique_ptr< MultiFab >> & | mapfac, | ||
| const std::unique_ptr< MultiFab > & | z_phys_nd, | ||
| const TurbChoice & | turbChoice, | ||
| const Real | const_grav, | ||
| std::unique_ptr< SurfaceLayer > & | , | ||
| const MoistureComponentIndices & | moisture_indices, | ||
| const MultiFab * | xvel, | ||
| const MultiFab * | yvel | ||
| ) |
Function for computing the turbulent viscosity with LES.
- Parameters
-
[in] Tau_lev strain at this level [in] cons_in cell center conserved quantities [out] eddyViscosity turbulent viscosity [in] Hfx1 heat flux in x-dir [in] Hfx2 heat flux in y-dir [in] Hfx3 heat flux in z-dir [in] Diss dissipation of turbulent kinetic energy [in] geom problem geometry [in] mapfac map factors [in] turbChoice container with turbulence parameters [in] xvel x-direction velocity (for moist Ri correction) [in] yvel y-direction velocity (for moist Ri correction)
244 Real DeltaH = (isotropic) ? length : std::sqrt(one / (dxInv * mf_u(i,j,0) * dyInv * mf_v(i,j,0)));
274 hfx_z(i,j,k) = -mu_turb(i,j,k,EddyDiff::Theta_v) * dtheta_dz; // (rho*w)' theta' [kg m^-2 s^-1 K]
AMREX_GPU_DEVICE AMREX_FORCE_INLINE amrex::Real ComputeSmnSmn2D(int &i, int &j, int &k, const amrex::Array4< amrex::Real const > &tau11, const amrex::Array4< amrex::Real const > &tau22, const amrex::Array4< amrex::Real const > &tau12)
Definition: ERF_EddyViscosity.H:206
AMREX_GPU_DEVICE AMREX_FORCE_INLINE amrex::Real ComputeSmnSmn(int &i, int &j, int &k, const amrex::Array4< amrex::Real const > &tau11, const amrex::Array4< amrex::Real const > &tau22, const amrex::Array4< amrex::Real const > &tau33, const amrex::Array4< amrex::Real const > &tau12, const amrex::Array4< amrex::Real const > &tau13, const amrex::Array4< amrex::Real const > &tau23)
Definition: ERF_EddyViscosity.H:85
amrex::GpuArray< Real, AMREX_SPACEDIM > dxInv
Definition: ERF_InitCustomPertVels_ParticleTests.H:17
AMREX_GPU_DEVICE AMREX_FORCE_INLINE amrex::Real GetThetav(const int &i, const int &j, const int &k, const amrex::Array4< amrex::Real const > &cell_data, const MoistureComponentIndices &moisture_indices)
Definition: ERF_MoistUtils.H:72
AMREX_GPU_DEVICE AMREX_FORCE_INLINE amrex::Real GetThetal(const int &i, const int &j, const int &k, const amrex::Array4< amrex::Real const > &cell_data, const MoistureComponentIndices &moisture_indices)
Definition: ERF_MoistUtils.H:128
AMREX_FORCE_INLINE IntVect offset(const int face_dir, const int normal)
Definition: ERF_ReadBndryPlanes.cpp:28
AMREX_GPU_DEVICE AMREX_FORCE_INLINE amrex::Real StabilityFunction(amrex::Real Ri, amrex::Real Ri_crit)
Definition: ERF_RichardsonNumber.H:386
AMREX_GPU_DEVICE AMREX_FORCE_INLINE amrex::Real ComputeVerticalShear2(int i, int j, int k, amrex::Real dzInv, const amrex::Array4< const amrex::Real > &u, const amrex::Array4< const amrex::Real > &v)
Definition: ERF_RichardsonNumber.H:281
AMREX_GPU_DEVICE AMREX_FORCE_INLINE amrex::Real ComputeRichardson(amrex::Real N2_moist, amrex::Real S2_vert)
Definition: ERF_RichardsonNumber.H:370
AMREX_GPU_DEVICE AMREX_FORCE_INLINE amrex::Real ComputeN2(int i, int j, int k, amrex::Real dzInv, amrex::Real const_grav, const amrex::Array4< const amrex::Real > &cell_data, const MoistureComponentIndices &moisture_indices)
Definition: ERF_RichardsonNumber.H:126
AMREX_FORCE_INLINE AMREX_GPU_DEVICE amrex::Real Compute_h_zeta_AtCellCenter(const int &i, const int &j, const int &k, const amrex::GpuArray< amrex::Real, AMREX_SPACEDIM > &cellSizeInv, const amrex::Array4< const amrex::Real > &z_nd)
Definition: ERF_TerrainMetrics.H:55
real(c_double), parameter epsilon
Definition: ERF_module_model_constants.F90:12
Referenced by ComputeTurbulentViscosity().
Here is the call graph for this function:
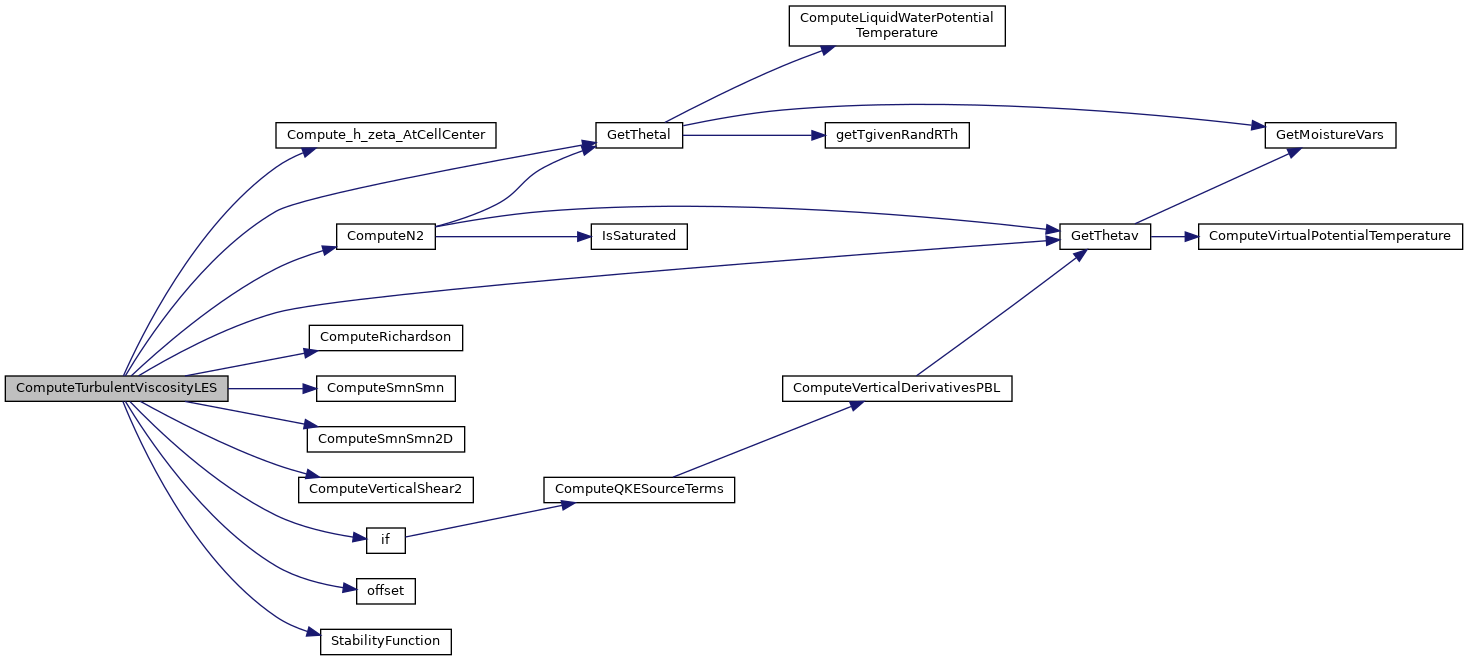
Here is the caller graph for this function:

◆ ComputeTurbulentViscosityLES_EB()
| void ComputeTurbulentViscosityLES_EB | ( | Vector< std::unique_ptr< MultiFab >> & | Tau_lev, |
| const MultiFab & | cons_in, | ||
| MultiFab & | eddyViscosity, | ||
| MultiFab & | Hfx1, | ||
| MultiFab & | Hfx2, | ||
| MultiFab & | Hfx3, | ||
| const Geometry & | geom, | ||
| Vector< std::unique_ptr< MultiFab >> & | mapfac, | ||
| const TurbChoice & | turbChoice, | ||
| const Real | const_grav, | ||
| [[maybe_unused] ] const SolverChoice & | solverChoice, | ||
| std::unique_ptr< SurfaceLayer > & | , | ||
| const MoistureComponentIndices & | moisture_indices, | ||
| const eb_ & | ebfact, | ||
| const MultiFab * | xvel, | ||
| const MultiFab * | yvel | ||
| ) |
400 Array4<const EBCellFlag> c_cflag = (ebfact.get_const_factory())->getMultiEBCellFlagFab()[mfi].const_array();
401 Array4<const EBCellFlag> u_cflag = (ebfact.get_u_const_factory())->getMultiEBCellFlagFab()[mfi].const_array();
402 Array4<const EBCellFlag> v_cflag = (ebfact.get_v_const_factory())->getMultiEBCellFlagFab()[mfi].const_array();
403 Array4<const EBCellFlag> w_cflag = (ebfact.get_w_const_factory())->getMultiEBCellFlagFab()[mfi].const_array();
417 SmnSmn = ComputeSmnSmn_EB(i,j,k,tau11,tau22,tau33,tau12,tau13,tau23,c_cflag,u_cflag,v_cflag,w_cflag);
AMREX_GPU_DEVICE AMREX_FORCE_INLINE amrex::Real ComputeSmnSmn_EB(int &i, int &j, int &k, const amrex::Array4< amrex::Real const > &tau11, const amrex::Array4< amrex::Real const > &tau22, const amrex::Array4< amrex::Real const > &tau33, const amrex::Array4< amrex::Real const > &tau12, const amrex::Array4< amrex::Real const > &tau13, const amrex::Array4< amrex::Real const > &tau23, const amrex::Array4< const amrex::EBCellFlag > &c_cflag, const amrex::Array4< const amrex::EBCellFlag > &u_cflag, const amrex::Array4< const amrex::EBCellFlag > &v_cflag, const amrex::Array4< const amrex::EBCellFlag > &w_cflag)
Definition: ERF_EddyViscosity.H:112
AMREX_GPU_DEVICE AMREX_FORCE_INLINE amrex::Real ComputeVerticalShear2_EB(int i, int j, int k, const amrex::Array4< const amrex::EBCellFlag > &c_cflag, const amrex::Array4< const amrex::Real > &u_vfrac, const amrex::Array4< const amrex::Real > &v_vfrac, amrex::Real dzInv, const amrex::Array4< const amrex::Real > &u, const amrex::Array4< const amrex::Real > &v)
Definition: ERF_RichardsonNumber.H:303
AMREX_GPU_DEVICE AMREX_FORCE_INLINE amrex::Real ComputeN2_EB(int i, int j, int k, const amrex::Array4< const amrex::EBCellFlag > &c_cflag, amrex::Real dzInv, amrex::Real const_grav, const amrex::Array4< const amrex::Real > &cell_data, const MoistureComponentIndices &moisture_indices)
Definition: ERF_RichardsonNumber.H:175
const std::unique_ptr< amrex::EBFArrayBoxFactory > & get_const_factory() const noexcept
Definition: ERF_EB.H:46
Referenced by ComputeTurbulentViscosity().
Here is the call graph for this function:
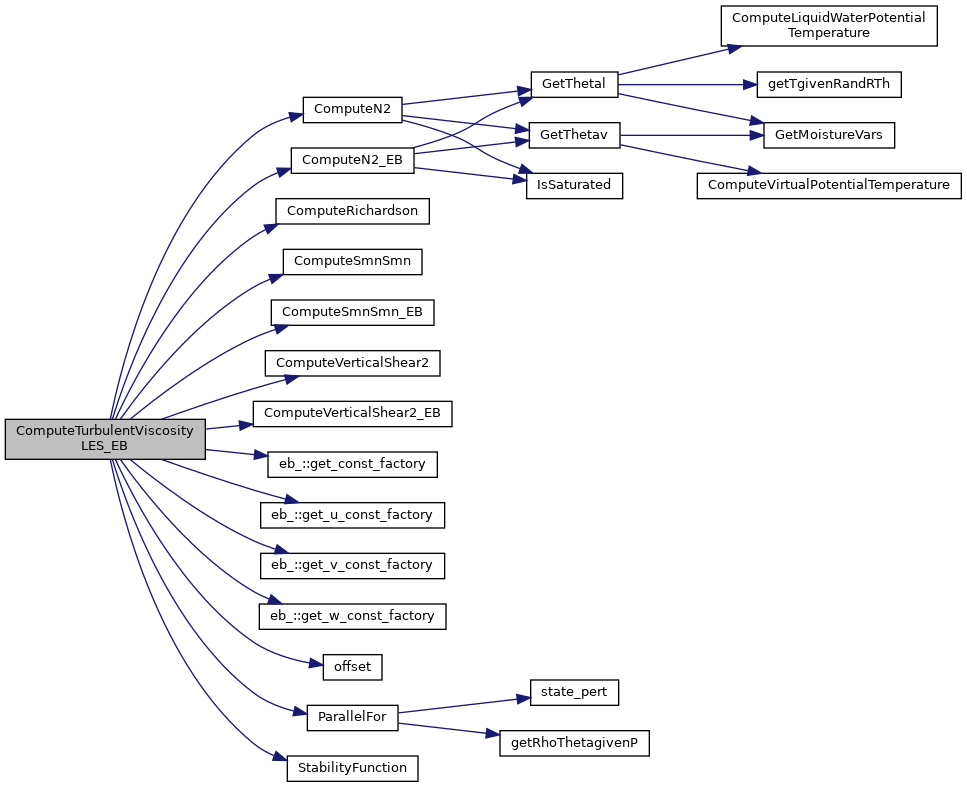
Here is the caller graph for this function:

◆ ComputeTurbulentViscosityRANS()
| void ComputeTurbulentViscosityRANS | ( | Vector< std::unique_ptr< MultiFab >> & | , |
| const MultiFab & | cons_in, | ||
| const MultiFab & | wdist, | ||
| MultiFab & | eddyViscosity, | ||
| MultiFab & | Hfx1, | ||
| MultiFab & | Hfx2, | ||
| MultiFab & | Hfx3, | ||
| MultiFab & | Diss, | ||
| const Geometry & | geom, | ||
| bool | use_terrain_fitted_coords, | ||
| Vector< std::unique_ptr< MultiFab >> & | , | ||
| const std::unique_ptr< MultiFab > & | z_phys_nd, | ||
| const TurbChoice & | turbChoice, | ||
| const Real | const_grav, | ||
| std::unique_ptr< SurfaceLayer > & | SurfLayer, | ||
| const MultiFab * | z_0 | ||
| ) |
Function for computing the eddy viscosity with RANS.
- Parameters
-
[in] Tau_lev strain at this level [in] cons_in cell center conserved quantities [out] eddyViscosity turbulent viscosity [in] Hfx1 heat flux in x-dir [in] Hfx2 heat flux in y-dir [in] Hfx3 heat flux in z-dir [in] Diss dissipation of turbulent kinetic energy [in] geom problem geometry [in] mapfac map factor [in] turbChoice container with turbulence parameters
616 const Array4<Real const>& z0_arr = (use_SurfLayer) ? z_0->const_array(mfi) : Array4<Real const>{};
685 Rt = (Rt >= Rt_crit) ? Rt : std::max(Rt, Rt - (Rt - Rt_crit)*(Rt - Rt_crit) / (Rt + Rt_min - 2*Rt_crit));
710 hfx_z(i, j, k) = -mu_turb(i, j, k, EddyDiff::Theta_v) * dtheta_dz; // (rho*w)' theta' [kg m^-2 s^-1 K]
Referenced by ComputeTurbulentViscosity().
Here is the call graph for this function:

Here is the caller graph for this function:
